March 5, 2020
Data News Roundup – Thursday, March 5th
A new, independent survey by AtScale, Cloudera and ODPi, a Linux Foundation project, delivered some surprising results. In particular, there were 3 takeaways that are noteworthy which every enterprise should keep in mind when working through their future data strategy.
Hadoop is Still Alive & Kicking
With the consolidation of the Hadoop vendors and the popularity of the new cloud data warehouses like Google BigQuery, Snowflake and Amazon Redshift, it’s clear that Hadoop did not fulfill its promise of becoming the data platform. I expected our survey responses to show a trend where enterprises were decreasing or eliminating their investment in Hadoop in favor of these new cloud data platforms.
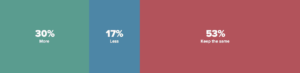
Instead, as you can see below, 30% of respondents indicated they planned to invest more in open source Hadoop while only 17% planned on reducing their investment.
Source: 2020 Big Data & Analytics Maturity Survey
In these results, it’s clear that Hadoop has found a place in the enterprise data stack. The takeaway for me: there is no single data platform that works for all data types and workloads so make sure your data and analytics strategy supports data lakes, data warehouses, on premise and in the cloud.
Data Governance is Top of Mind
At AtScale, we listen to our customers closely and they are definitely telling us that our data governance and security features are becoming increasingly important to them. However, the survey results surprised even me in respondents’ data governance anxiety. I think these responses are indicative of the challenges IT has managing a multi-site, multi-platform world where just one slip up in data security and governance means losing your job.
As you can see in the chart below, 92% of respondents listed data governance as very important or important to them.
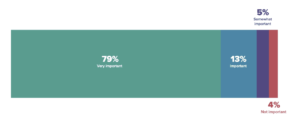
Source: 2020 Big Data & Analytics Maturity Survey
Yet, to date, most of the technology solutions in the market have been focused on data cataloging and policy management. These are critical functions, don’t get me wrong. However, just knowing that you have a data governance and security problem is not enough. Enterprises are looking for solutions that will enforce policies consistently across an increasing complicated landscape. That means every query needs governance and data platform specific features to do so are not up to the task nor are they the single control plane customers are looking for.
Traditional ETL is Increasingly Out of Favor
ETL is so 90s. When I was running data pipelines at Yahoo!, it became abundantly clear that moving and shrinking data for analytics wasn’t a viable, long term strategy. However, I continued to see enterprises fall back on this traditional, data movement-centric strategy.
So, I was surprised to see respondents indicate a sharp decrease in investment in traditional ETL tools and a movement away from a traditional data warehouse in favor of data virtualization.
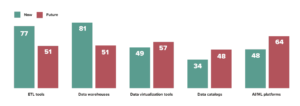
Source: 2020 Big Data & Analytics Maturity Survey
Of course, I think this trend makes sense and it’s great to see others come around to the same conclusion. As data disperses in multiple clouds and on-premises data platforms, I predict we’ll seem more enterprises invest in a “virtual data warehousing” strategy and move away from physical data movement.
As you can see in these survey results, enterprises are dealing with some tough challenges in the new world. We think this is a great time to consider a data virtualization solution like AtScale to kill many birds with one stone. Data Virtualization (DV) helps enterprises get control of their data assets in some critical ways:
- As a universal semantic layer, DV hides the physical implementation of the data while presenting a unified view of that data to any tool or application. That means everyone is speaking the same (semantic) language.
- DV is a great “man in the middle” approach to enforcing data governance and security consistently across the enterprise. Essentially, DV inspects every query creating a central audit trail and enforcement layer.
- DV is a valuablegreat tool for helping enterprises migrate their data assets to the cloud without a “rip and replace” strategy that is risky and disrupts downstream data consumers. By hiding the physical location of the data, DV provides IT with the aircover to migrate data to new clouds and/or platforms without end users even knowing about it.
To learn more, download the “2020 Big Data & Analytics Maturity Survey Results” report from www.atscale.com.
NEW BOOK